Update:
- Beta version 1.0 released.
- NDSS ‘19 talk (Feb 27) at San Diego
LipFuzzer Introduction
LipFuzzer aims to assess the problematic Intent Classifier (NDSS paper link) at a large scale. The tool generates potentially dangerous voice commands that are likely to incur semantic inconsistency such that a user reaches an unintended vApp/functionality (i.e. users think they use voice commands correctly but yield unwanted results).
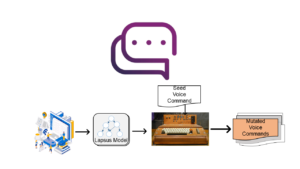
LipFuzzer design
--------------
| | * Pronounication
Seed Voice ==> | NLP Engine | ==> * Vocabulary
Command Input | | * Grammar
--------------
||
\/
------------------------
......... --------- | LipEngine |
/User / /Default/ |......................|
/Defined/ + /Fuzzing/ +++> | *Module_1 *Module_2 |
/Rules / /Rules / loading.. | *Module_3 ... |
--------- --------- | *Module_n |
------------------------
|| || ....
\/ \/
Potentially Dangerous
Voice Commands (Lapsus)
Seed Voice Command Input
The input can be any voice commands (in English). In our study, we mainly focus on Voice Assistant Applications (vApps).
NLPEngine
Natural language such as voice commands do not have enough information for fuzzing tasks mentioned earlier. We leverage NLP techniques to retrieve computational linguistic information to build LAPSUS Models. Pronunciation-level Information.
We choose phonemes as sound-level linguistic information since it is the basic sound unit. We extract phonemes from each word by leveraging CMU Pronouncing Dictionary in the NLTK package. For vocabulary linguistic information, we leverage basic string metric. In order to tackle the ambiguity of the natural language, we also use grammar-level linguistic information, i.e., PoS Tagging, Stemming and Lemmatization. In particular, PoS Tagging processes grammar information by tagging tenses and other word contexts. The stemming and the lemmatization are similar regarding functionality. The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form.
What are being used? We use the following example to demonstrate what are the linguistic data we used for fuzzing purpose. We show one example from coreNLP.

Fuzzing Rules
To instantiate each konwledge-transfered fuzzing rules, we define fuzzing rules based on retrived computational linguistic data. In detail, we set “matching” conditions and “actions” for mutation actions. Please check details in the Fuzzing Rule.
LipFuzzer learns from existing linguistic knowledge to find out potentially (and likely) dangerous voice commands. For example, we list one regional accent example in the follwoing:

LipEngine
LipEngine conducts actual mutation operations for voice commands. It consists of multipule modules that operates based on fuzzing rules.
Outputs
The output of LipFuzzer is a set of mutated voice command (Lapsus) that arguably easy to be mispoke by vApp users.
How to install LipFuzzer
Github
We make our code available on github. You can download it via following command:
git clonehttps://github.com/hypernovas/lipfuzzer.git
Lipfuzzer Dependency
We stand on the shoulders of giants, please be aware of the following dependency.
Stanford CoreNLP: You need to download the Enlgish version of CoreNLP tool package and use the path in LipFuzzer.
Please download and extract (you will need to donwload the zip version) the tool under the root folder for example you can see .jar files under:
./stanford-corenlp-full-2018-10-05/
Natural Language Toolkit (NLTK): Various ways can be used to install NLTK, for example:
sudo pip install -U nltk
Others: sudo pip install pyenchant sudo pip install inflect
Try it out
After installed LipFuzzer, use first.py file to demonstrate a simple fuzzing test.
python first.py
More about LipFuzzer
Current Version Features:
- Phonemes, Lemma, Dependency, vocabulary based fuzzing
- Default LipEngine Modules are provided
- Custom Modules available
- Generate new fuzzing rules
Ongoing/future Development
Better linguistic model with automated weight training available.
Advanced chetbot for auto-checking.
Contact:
yangyong@tamu.edu
Publication:
[1] Yangyong Zhang, Lei Xu, Abner Mendoza, Guangliang Yang, Phakpoom Chinprutthiwong, Guofei Gu. “Life after Speech Recognition: Fuzzing Semantic Misinterpretation for Voice Assistant Applications.” In Proc. of the Network and Distributed System Security Symposium (NDSS’19), San Diego, California, Feb. 2019. [pdf] [bib]LipFuzzer Module List
We list a part of modules that is being used in the LipFuzzer:
Module_Zero: (Vocabulary) Simple Word Mutation
This swapping function switch between words, for example, swap “crypto” with “crypt”. Thus, in a sentence of “Alexa, enable Crypto Wallet.” will have a result of Lapsus “Alexa, enable Crypt Wallet.”. Please note this can also be defined by Module_Three easily.
Module_One: (Dependency) Word Addition
Dependency-based linguistic information can also be used. This module supports word’s addition based on word’s dependency. For example, given an utterance. For example, for ‘Hey Google, Crypto Wallet’. It has NNP compound NNP structure (NNP = singular proper noun), Then, it can add ‘my’ in front. This results in ‘Hey Google, My Crypto Wallet’.
Module_Two: (Dependency) DT Remover
In this module, DT (Determiner) will be removed based on certain conditions. For example, if there’s a compound Noun words combination, the DT (e.g., The) could be igorned by the speaker.
Module_Three: (Dependency) DT Addition
DT could be added even DT is not mentioned in the template voice command. We could add “a” or “the” in the speech which is a common speech error we observe.
Module_Four: (Phoneme) Phoneme Mutation
We mutate phoneme(s) based on rules. For example, for regional accent, we could mutate “S-T-AO-R ” (st-ore with US English) to “S-T-AW-L” (st-awh) based the example shown previously.
Module_Five: Prefix Mutation
Sometimes, prefix can be ignored. For example, “pre-”, “ex-”, “un-”, etc.
Module_Six: Suffix
Suffix is a even more popular Lapsus, people tends to add “-s”, “-ed”, “-ly”, etc.
and more in github …
https://github.tamu.edu/yangyong/lipfuzzerbeta/tree/master/modules
Write Your Own Module
Accessing linguistic data
- Original voice command is stored in data[‘ut’]
- Tokenized words are stored in data[‘to’]
- Dependency data is store in data[‘de’].
- data[‘ph’] for phonemes.
Module_Two is shown in the following, you may access these data and create your own modules:
def module_two(self, data, rule):
#PoS = Part of Speech
pos_map = {}
for pos in data['de']:
pos_map[pos[0][0]] = pos[0][1]
pos_map[pos[2][0]] = pos[2][1]
pos_match = rule['match']
for word, pos in pos_map.items():
if pos == pos_match:
data['ut'] = data['ut'].replace(word, "")
Useful links:
Fuzzing Rule
In LipFuzzer, rule is a computable representation of knowledge. As different types of computational linguistic knowldege are used. One piece of knowledge can be explained by different types of modules (i.e., modules naturally classify the rules into different categories)
Module_One Example Rule:
In the following example we show a determinater removal rule. When the word is in the form of “NNP: Proper noun, singular”(PoS Tagging), then we remove the determiner (DT) if there is one. This models the knowledge that people could ignore “a” or “the” in their speech. Sometime, people could also add “a” for “NNS: Noun, plural” words.
{'action': 'remove', 'match': 'NNP', 'name': 'mod2', 'module': 2}
Write your Own Fuzzing Rule
Although any all levels of linguistic information can be used to develope rules. Sometime, it is preferred to use simple swappings (e.g., string or word swapping) because it is more rubost in terms of both fuzzing and audio synthesis.
r = rulePack()
# firt match then action
r.addRule(1, ('NNP', 'compound', 'NNP'), ('front', 'a'), 'mod1')
r.genRuleFile('ruleFile.txt')
Update rules in existing rule file
r.updateRule(1, 2, 'NNPS', 'remove', 'mod2')
r.addRuleSet('testRuleIO.txt')