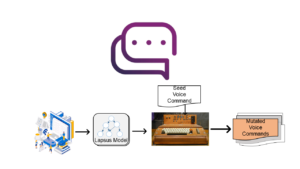
LipFuzzer aims to assess vApp’s problematic Intent Classifier at a large scale. The tool generates potentially dangerous voice commands that are likely to incur semantic inconsistency such that a user reaches an unintended vApp/functionality (i.e. users think they use voice commands correctly but yield unwanted results).
Learn More…
Learn More…